Ventajas y desventajas de las máquinas de estados finitos: casos de conmutación, punteros C/C++ y tablas de búsqueda (Parte II)
Esta es la segunda y última parte de la implementación de nuestra Máquina de Estados Finitos (MSF). Puedes consultar la primera parte de la serie y aprender más sobre las Máquinas de Estados Finitos aquí.
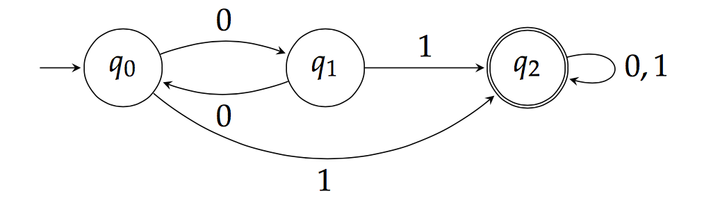
Las máquinas de estados finitos (MEF) son simplemente un cálculo matemático de causas y eventos. Basándose en estados, una MEF calcula una serie de eventos según el estado de sus entradas. Por ejemplo, para un estado llamado SENSOR_READ , una MEF podría activar un relé (también conocido como evento de control) o enviar una alerta externa si la lectura de un sensor supera un valor umbral. Los estados son la esencia de la MEF: determinan su comportamiento interno o sus interacciones con el entorno, como aceptar entradas o producir salidas, lo que puede provocar un cambio de estado en el sistema. Como ingenieros de hardware, nuestra labor consiste en seleccionar los estados y eventos de activación adecuados para la MEF, con el fin de obtener el comportamiento deseado que se ajuste a las necesidades de nuestro proyecto.
En la primera parte de este tutorial sobre máquinas de estados finitos (FSM), creamos una FSM utilizando la implementación clásica de switch-case. Ahora, exploraremos cómo crear una FSM utilizando punteros de C/C++, lo que le permitirá desarrollar una aplicación más robusta con requisitos de mantenimiento de firmware más sencillos.
NOTA: El código utilizado en este tutorial fue presentado en el Arduino Day 2018 en Bogotá por José García, uno de los Ubidots . Puedes encontrar los ejemplos de código completos y las notas del orador aquí.
Desventajas de la caja de conmutación:
En la primera parte de nuestro tutorial sobre máquinas de estados finitos (FSM), vimos las estructuras switch-case y cómo implementar una rutina sencilla. Ahora, ampliaremos esta idea introduciendo los punteros y cómo aplicarlos para simplificar la rutina de tu FSM.
Una de switch-case es muy similar a una if-else ; nuestro firmware recorrerá cada caso, evaluándolos para ver si se cumple la condición del caso desencadenante. Veamos un ejemplo de rutina a continuación:
switch(estado) { caso 1: /* crear algunas cosas para el estado 1 */ estado = 2; romper; caso 2: /* crear algunas cosas para el estado 2 */ estado = 3; romper; caso 3: /* crear algunas cosas para el estado 3 */ estado = 1; romper; predeterminado: /* crear algunas cosas por defecto */ estado = 1; }
En el código anterior, encontrará una FSM simple con tres estados. En el bucle infinito, el firmware pasará al primer caso, comprobando si la variable de estado es igual a uno. Si es así, ejecuta su rutina; si no, procede al caso 2, donde vuelve a comprobar el valor del estado. Si el caso 2 no se cumple, la ejecución del código pasará al caso 3, y así sucesivamente hasta que se alcance el estado o se agoten los casos.
Antes de entrar en el código, vamos a comprender un poco mejor algunas de las posibles desventajas de las switch-case o if-else para que podamos ver cómo mejorar el desarrollo de nuestro firmware.
Supongamos que la variable de estado inicial es 3: nuestro firmware tendrá que realizar tres validaciones de valores diferentes. Esto puede no ser un problema para una FSM pequeña, pero imaginemos una máquina de producción industrial típica con cientos o miles de estados. La rutina necesitará realizar varias comprobaciones de valores inútiles, lo que en última instancia resultará en un uso ineficiente de los recursos. Esta ineficiencia se convierte en nuestra primera desventaja: el microcontrolador tiene recursos limitados y se verá sobrecargado con rutinas FSM ineficientes. Por lo tanto, es nuestro deber como ingenieros ahorrar la mayor cantidad posible de recursos computacionales en el microcontrolador.
Ahora imagina una FSM con miles de estados: si eres un desarrollador nuevo y necesitas implementar un cambio en uno de esos estados, tendrás que revisar miles de líneas de código dentro de tu rutina principal loop(). Esta rutina suele incluir mucho código no relacionado con la máquina, por lo que puede ser difícil de depurar si centras toda la lógica de la FSM dentro de la rutina principal loop().
Y, por último, un código con miles de if-else o switch-case no es elegante ni legible para la mayoría de los programadores de sistemas embebidos.
Punteros C/C++
Ahora veamos cómo podemos implementar una FSM concisa usando punteros de C/C++. Un puntero, como su nombre indica, apunta a algún punto dentro del microcontrolador. En C/C++, un puntero apunta a una dirección de memoria con la intención de recuperar información. Un puntero se utiliza para obtener el valor almacenado de una variable durante la ejecución sin conocer la dirección de memoria de la variable. Usados correctamente, los punteros pueden ser de gran ayuda para la estructura de la rutina y simplificar el mantenimiento y la edición futuros.
- Ejemplo de código de punto:
int a = 1462; int miPunteroDirección = &a; int miValorDirección = *miPunteroDirección;
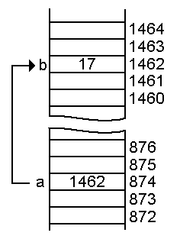
Analicemos qué sucede en el código anterior. La variable `myAddressPointer` apunta a la dirección de memoria de la variable `a` (1462), mientras que la variable `myAddressValue` recupera el valor de la dirección de memoria a la que apunta `myAddressPointer`. Por lo tanto, se espera obtener el valor 874 de `myAddressPointer` y 1462 de `myAddressValue`. ¿Por qué es útil esto? Porque no solo almacenamos valores en memoria, sino también funciones y comportamientos de métodos. Por ejemplo, el espacio de memoria 874 almacena el valor 1462, pero esta dirección de almacenamiento también puede gestionar funciones para calcular la intensidad de corriente en kA. Los punteros nos dan acceso a esta funcionalidad adicional y a la usabilidad de la dirección de memoria sin necesidad de declarar una instrucción de función en otra parte del código. Un puntero a función típico se puede implementar como se muestra a continuación:
vacío (*funcPtr) (vacío);
¿Te imaginas usar esta herramienta en nuestra FSM? Podemos crear un puntero dinámico que apunte a las diferentes funciones o estados de nuestra FSM en lugar de una variable. Si tenemos una sola variable que almacena un puntero que cambia dinámicamente, podemos cambiar los estados de la FSM según las condiciones de entrada.
Tablas de búsqueda
Repasemos otro concepto importante: las tablas de búsqueda o LUT. Las LUT ofrecen una forma ordenada de almacenar datos, en estructuras básicas que almacenan valores predefinidos. Nos serán útiles para almacenar datos dentro de nuestros valores FSM.
La principal ventaja de las LUT es que, si se declaran estáticamente, se puede acceder a sus valores mediante direcciones de memoria, lo cual es una forma muy efectiva de acceder a valores en C/C++. A continuación, se muestra una declaración típica de una LUT FSM:

void (*const state_table [MAX_STATES][MAX_EVENTS]) (void) = { acción_s1_e1, acción_s1_e2 }, /* procedimientos para el estado { acción_s2_e1, acción_s2_e2 }, /* procedimientos para el estado { acción_s3_e1, acción_s3_e2 } /* procedimientos para el estado };
Es mucho para digerir, pero estos conceptos son fundamentales para implementar nuestro nuevo y eficiente FSM. Ahora, vamos a codificarlo para que vean con qué facilidad este tipo de FSM puede crecer con el tiempo.
Nota: El código completo de la máquina de estados finitos (FSM) se puede encontrar aquí ; lo hemos dividido en 5 partes para simplificarlo.
Codificación
Crearemos un módulo de funciones de control (FSM) simple para implementar una rutina de parpadeo de LED. Puedes adaptar el ejemplo a tus necesidades. El FSM tendrá dos estados: LED encendido y LED apagado, y el LED se encenderá y apagará cada segundo. ¡Comencemos!
/* CONFIGURACIÓN DE LA MÁQUINA DE ESTADOS */ /* Estados válidos de la máquina de estados */ typedef enum { LED_ON, LED_OFF, NUM_STATES } StateType; /* Estructura de la tabla de la máquina de estados */ typedef struct { StateType State; // Crear el puntero de función void (*function)(void); } StateMachineType;
En la primera parte, implementamos nuestra tabla de búsqueda (LUT) para crear estados. Para mayor comodidad, utilizamos el método `enum()` para asignar valores de 0 y 1 a nuestros estados. El número máximo de estados también se establece en 2, lo cual tiene sentido en nuestra arquitectura de máquina de estados finitos (FSM). Este tipo de definición se denominará ` StatedType` para poder referirnos a él más adelante en nuestro código.
A continuación, creamos una estructura para almacenar nuestros estados. También declaramos un puntero denominado función, que será nuestro puntero de memoria dinámica para llamar a los diferentes estados de FSM.
/* Declaración inicial del estado y funciones del SM */ StateType SmState = LED_ON; void Sm_LED_ON(); void Sm_LED_OFF(); /* Tabla de búsqueda con estados y funciones a ejecutar */ StateMachineType StateMachine[] = { {LED_ON, Sm_LED_ON}, {LED_OFF, Sm_LED_OFF} };
Aquí, creamos una instancia con el estado inicial LED_ON, declaramos nuestros dos estados y finalmente creamos nuestra LUT. Las declaraciones de estado y el comportamiento están relacionados en la LUT, por lo que podemos acceder a los valores fácilmente a través de índices enteros . Para acceder al método sm_LED_ON(), por ejemplo, codificaremos algo como StateMachineInstance[0]; .
/* Rutinas de funciones de estado personalizadas */ void Sm_LED_ON() { // Código de función personalizada digitalWrite(LED_BUILTIN, HIGH); delay(1000); // Pasar al siguiente estado SmState = LED_OFF; } void Sm_LED_OFF() { // Código de función personalizada digitalWrite(LED_BUILTIN, LOW); delay(1000); // Pasar al siguiente estado SmState = LED_ON; }
En el código anterior, se implementa la lógica de nuestros métodos y no incluye nada especial además de la actualización del número de estado al final de cada función.
/* Rutina de cambio de estado de la función principal */ void Sm_Run(void) { // Se asegura de que el estado actual sea válido if (SmState < NUM_STATES) { (*StateMachine[SmState].function) (); } else { // Código de excepción de error Serial.println("[ERROR] Estado no válido"); } }
La funciónSm_Run() es el núcleo de nuestra máquina de estados finitos (FSM). Observa que usamos un puntero (*) para extraer la posición de memoria de la función de nuestra tabla de búsqueda (LUT), ya que accederemos dinámicamente a una posición de memoria en la LUT durante la ejecución. Sm_Run() siempre ejecutará varias instrucciones, también conocidas como eventos de la FSM, que ya están almacenadas en una dirección de memoria del microcontrolador.
/* FUNCIONES PRINCIPALES DE ARDUINO */ void setup() { // coloque aquí su código de configuración, para ejecutarlo una vez: pinMode(LED_BUILTIN, OUTPUT); } void loop() { // coloque aquí su código principal, para ejecutarlo repetidamente: Sm_Run(); }
Nuestras funciones principales de Arduino ahora son muy sencillas: el bucle infinito siempre se ejecuta con la rutina de cambio de estado definida previamente. Esta función gestionará el evento que activa y actualiza el estado actual de la FSM.
Conclusiones
En esta segunda parte de nuestra serie Máquinas de Estados Finitos y Punteros C/C++, revisamos las principales desventajas de las rutinas FSM en caso de conmutación e identificamos a los punteros como una opción adecuada y deseable para ahorrar memoria y aumentar la funcionalidad del microcontrolador.
A modo de resumen, aquí se presentan algunas de las ventajas y desventajas de usar punteros en su rutina de máquina de estados finitos:
Ventajas:
- Para agregar más estados, simplemente declare el nuevo método de transición y actualice la tabla de búsqueda; la función principal será la misma.
- No es necesario ejecutar cada instrucción if-else: el puntero permite que el firmware "vaya" al conjunto de instrucciones deseado en la memoria del microcontrolador.
- Esta es una forma concisa y profesional de implementar FSM.
Desventajas:
- Necesita más memoria estática para almacenar la tabla de búsqueda que almacena los eventos FSM.
